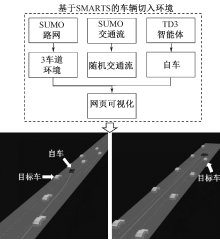
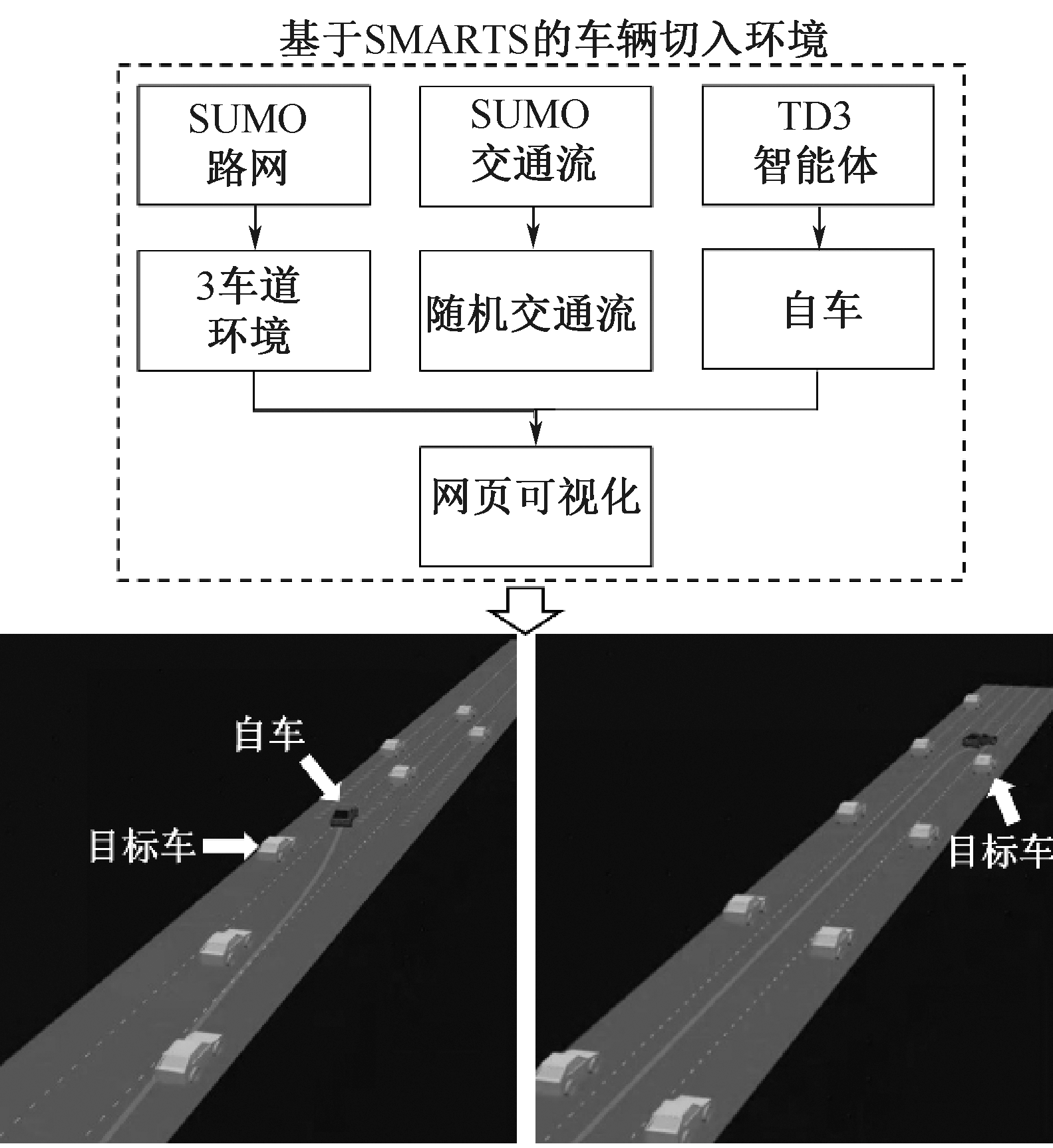
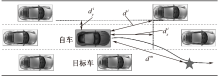
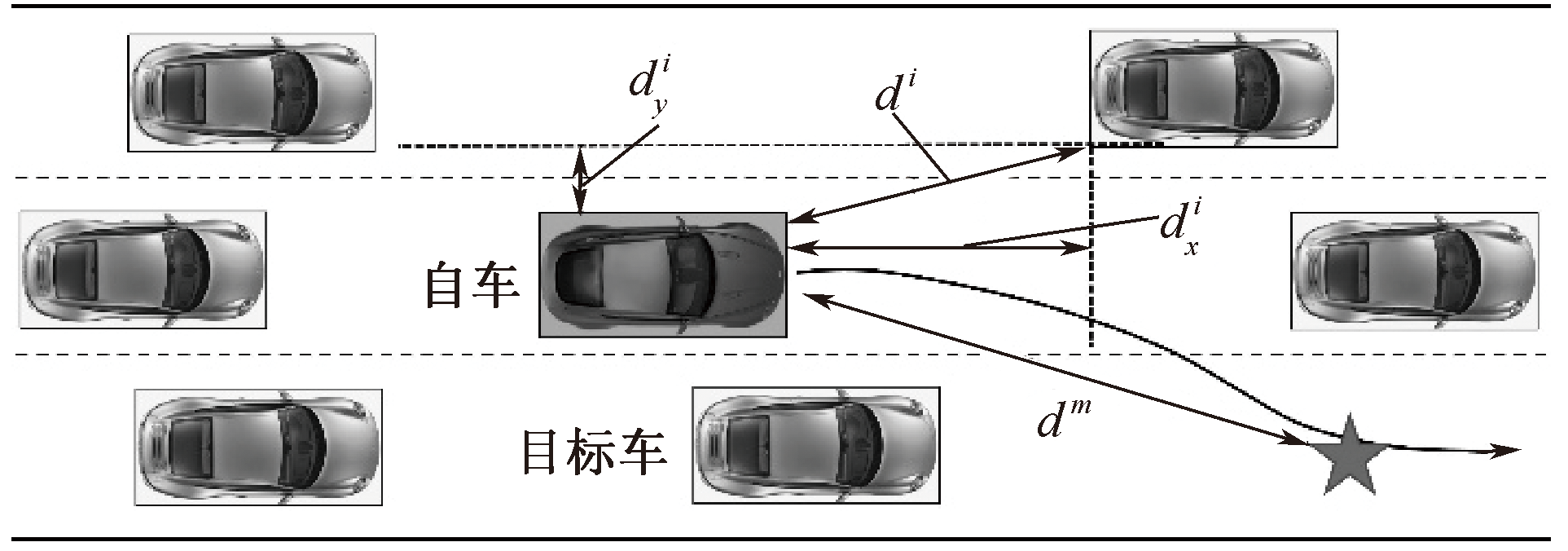
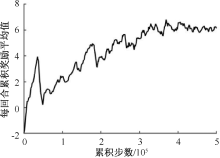
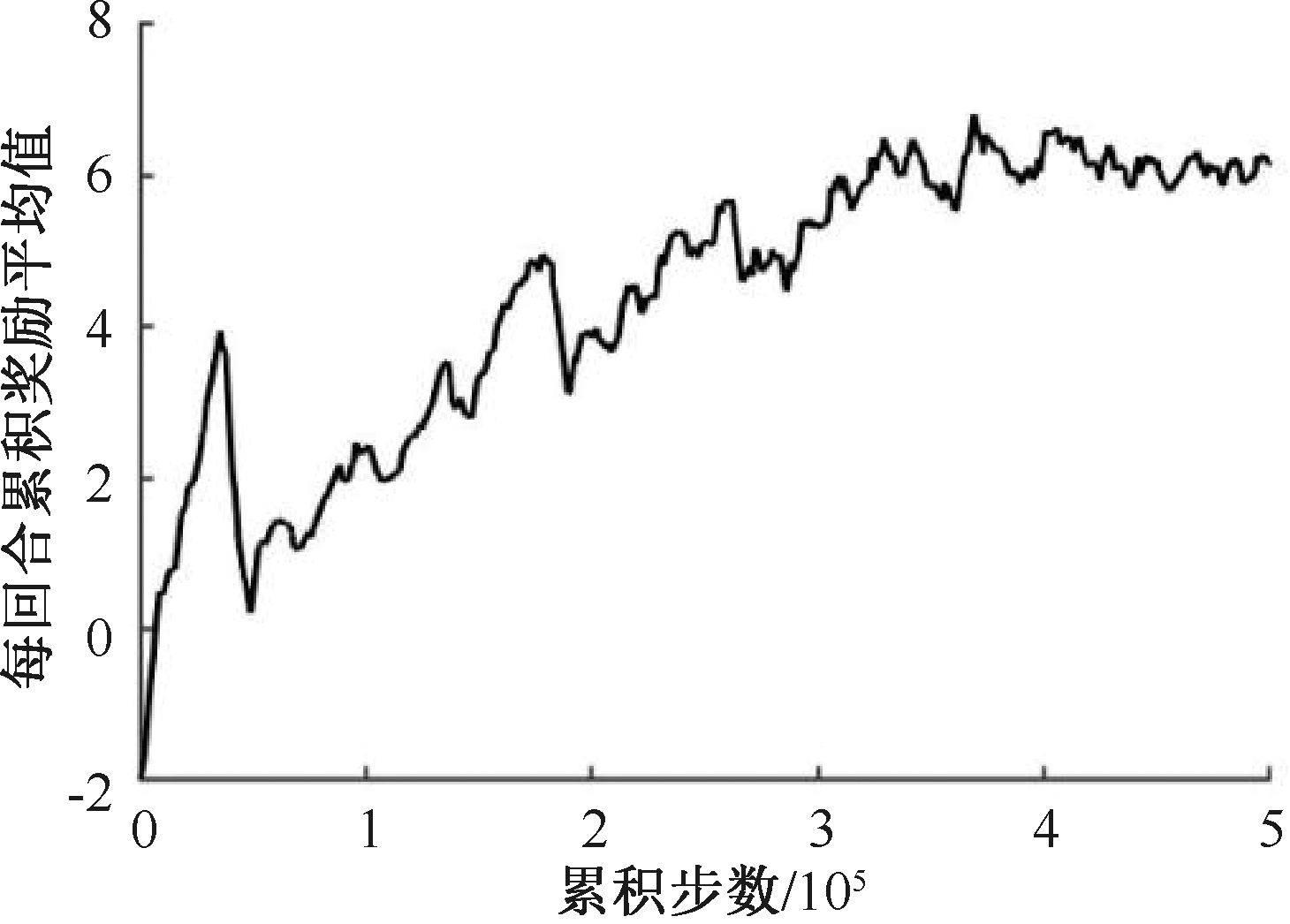
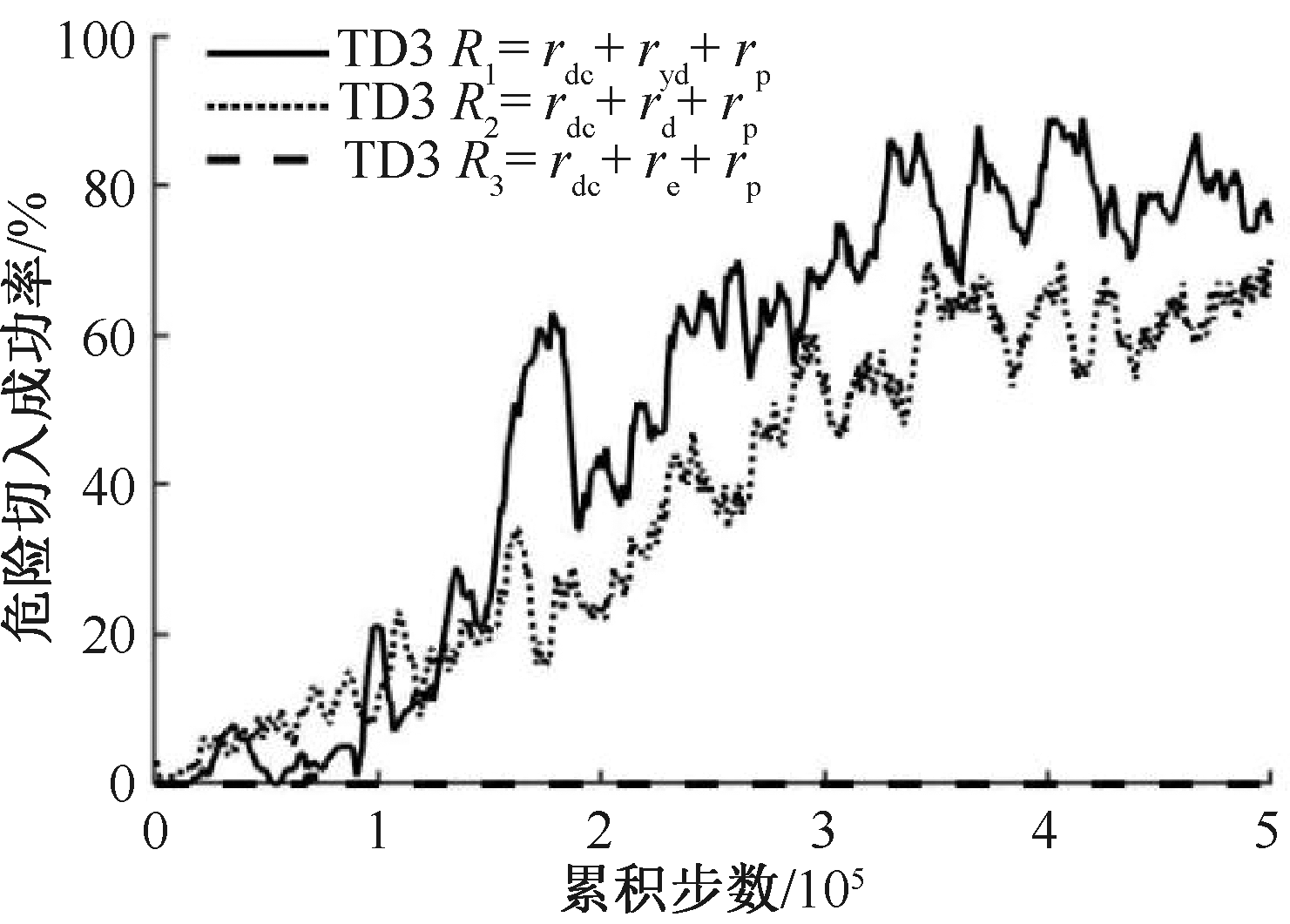
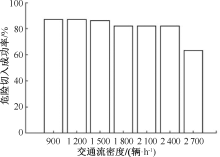
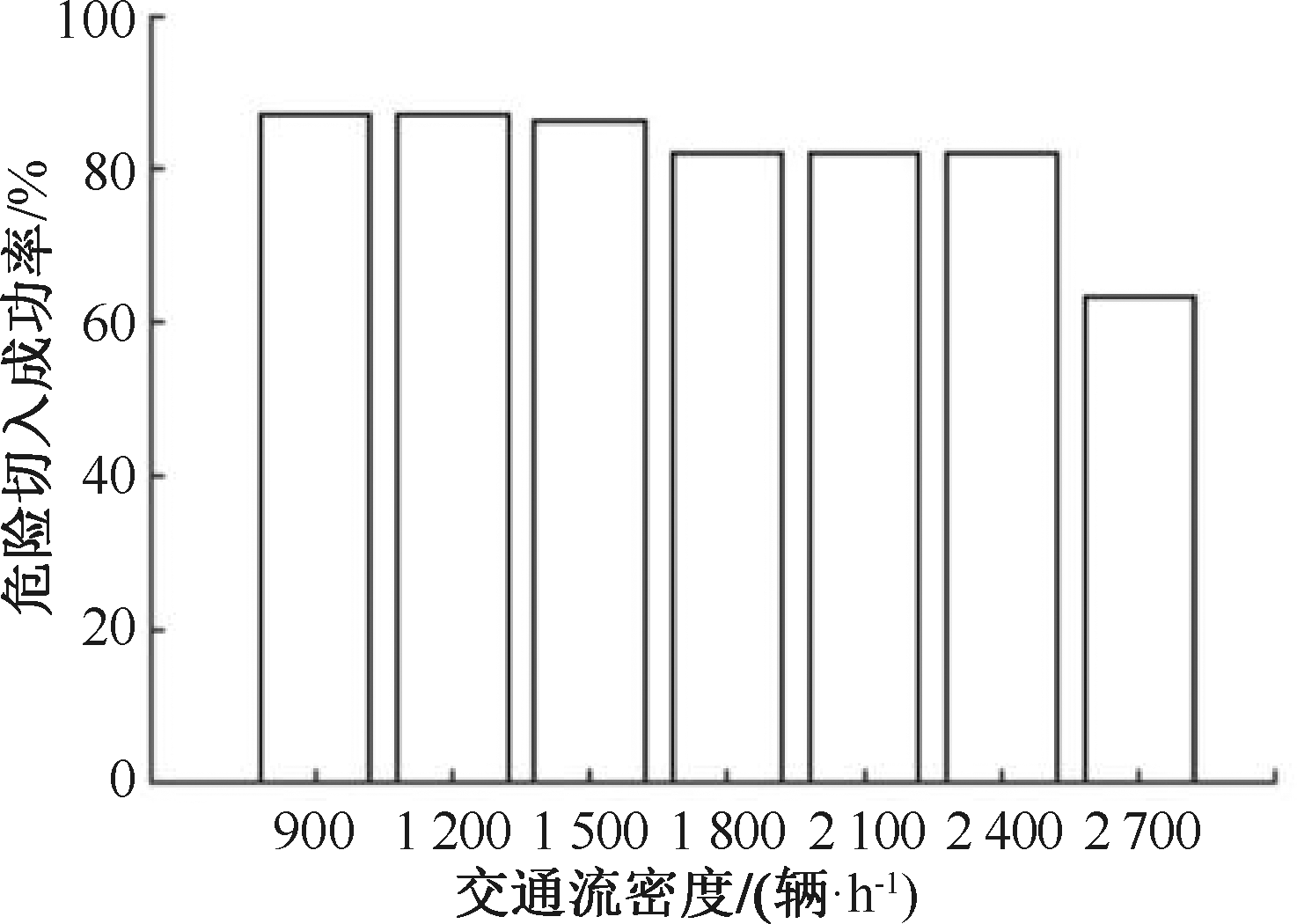
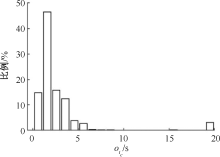
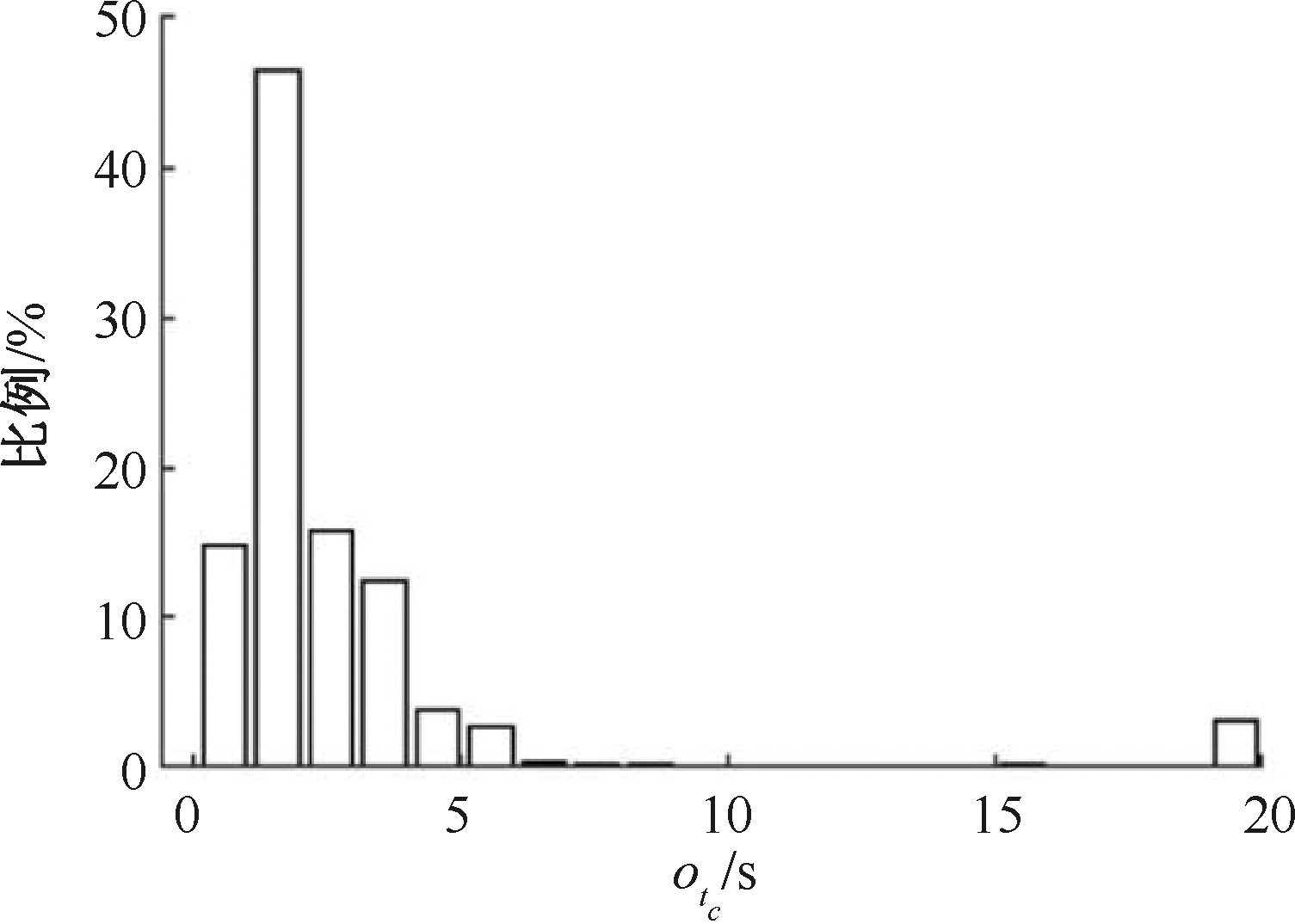
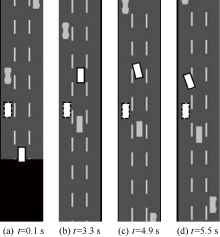
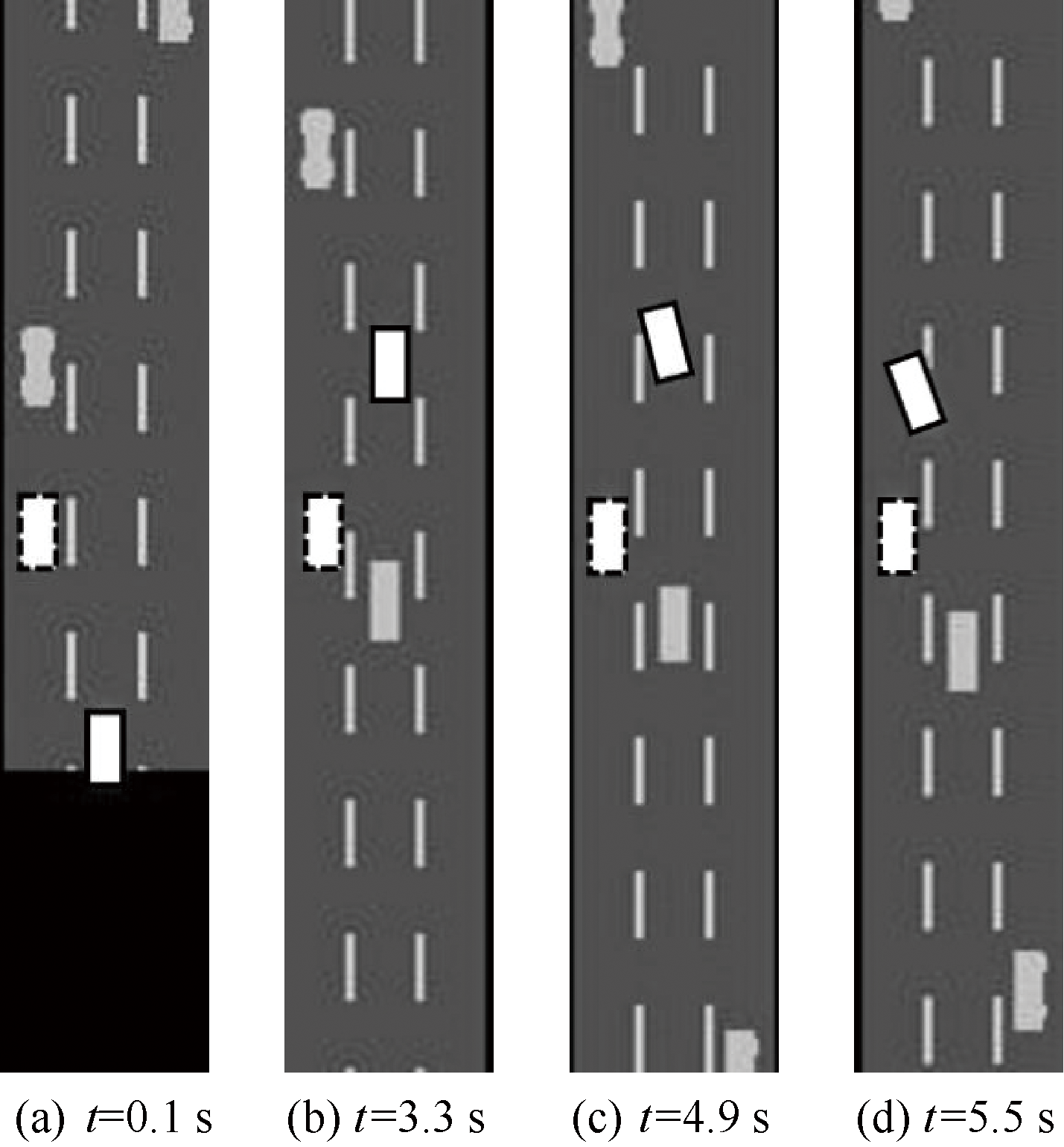
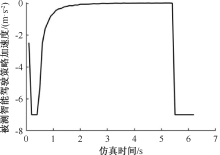
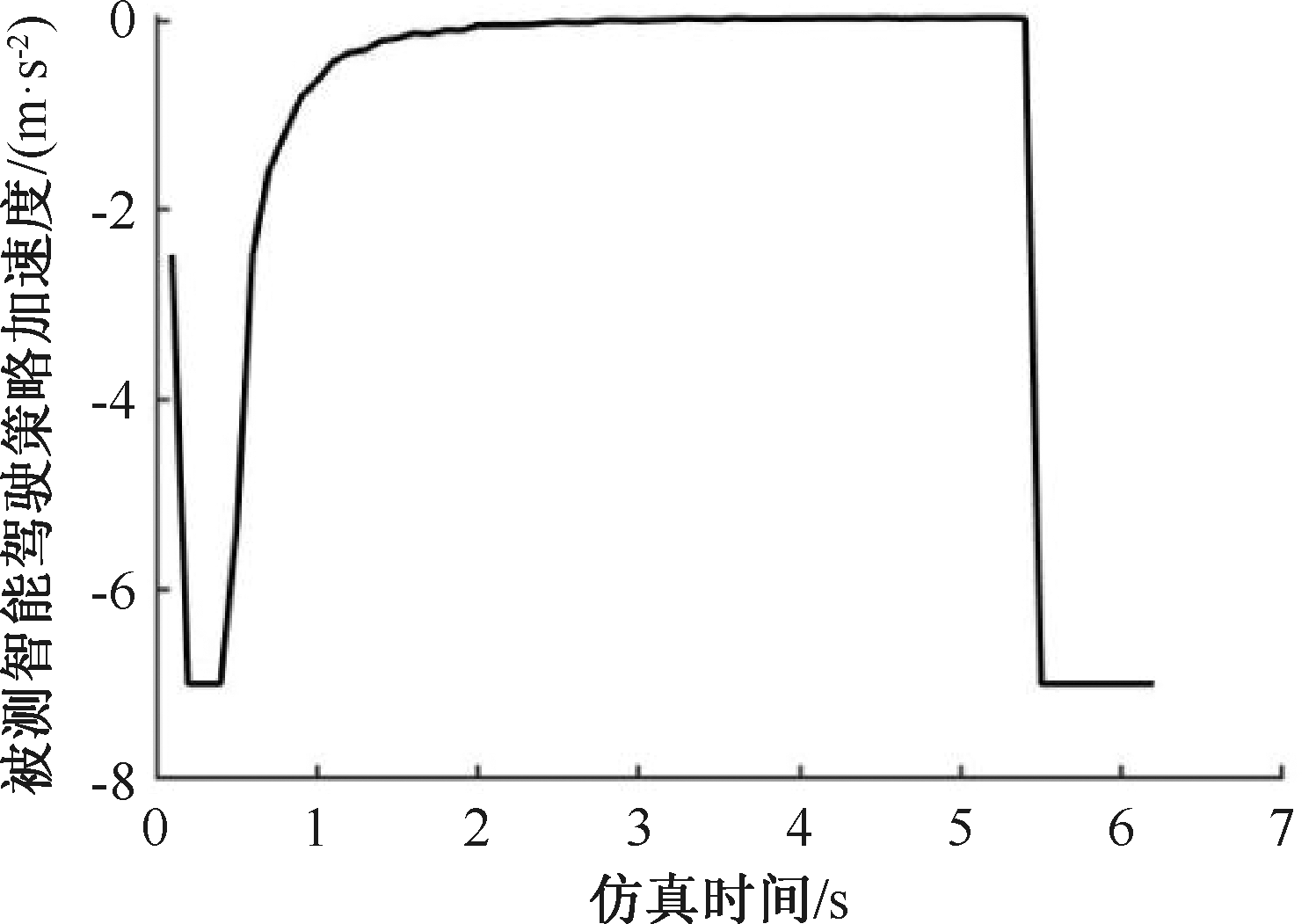
| [1] |
朱冰, 张培兴, 赵健, 等. 基于场景的自动驾驶汽车虚拟测试研究进展[J]. 中国公路学报, 2019, 32(6): 1-19.
doi: 10.19721/j.cnki.1001-7372.2019.06.001
|
|
ZHU Bing, ZHANG Peixing, ZHAO Jian, et al. Review of scenario-based virtual validation methods for automated vehicle[J]. China Journal of Highway and Transport, 2019, 32(6): 1-19.
doi: 10.19721/j.cnki.1001-7372.2019.06.001
|
| [2] |
邓伟文, 李江坤, 任秉韬, 等. 面向自动驾驶的仿真场景自动生成方法综述[J]. 中国公路学报, 2022, 35(1): 316-333.
doi: 10.19721/j.cnki.1001-7372.2022.01.027
|
|
DENG Weiwen, LI Jiangkun, REN Bingtao, et al. A survey on automatic simulation scenario generation methods for autonomous driving[J]. China Journal of Highway and Transport, 2022, 35(1): 316-333.
doi: 10.19721/j.cnki.1001-7372.2022.01.027
|
| [3] |
徐向阳, 胡文浩, 董红磊, 等. 自动驾驶汽车测试场景构建关键技术综述[J]. 汽车工程, 2021, 43(4): 610-619.
|
|
XU Xiangyang, HU Wenhao, DONG Honglei, et al. Review of key technologies for autonomous vehicle test scenario construction[J]. Automotive Engineering, 2021, 43(4): 610-619.
|
| [4] |
郭柏苍, 雒国凤, 金立生, 等. 面向自动驾驶虚拟测试的变道切入场景库构建方法[J]. 吉林大学学报:工学版, 2023, 53(11): 3130-3140.
|
|
GUO Baicang, LUO Guofeng, JIN Lisheng, et al. Construction method of cut-in scenario library for automatic driving virtual tests[J]. Journal of Jilin University: Engineering and Technology Edition, 2023, 53(11): 3130-3140.
|
| [5] |
赵祥模, 赵玉钰, 景首才, 等. 面向自动驾驶测试的危险变道场景泛化生成[J]. 自动化学报, 2023, 49 (10): 2211-2223.
|
|
ZHAO Xiangmo, ZHAO Yuyu, JING Shoucai, et al. Generalization generation of hazardous lane-changing scenarios for automated vehicle testing[J]. Acta Automatica Sinica, 2023, 49 (10): 2211-2223.
|
| [6] |
朱冰, 范天昕, 赵健, 等. 基于危险边界搜索的自动驾驶系统加速测试方法[J]. 吉林大学学报:工学版, 2023, 53(3): 704-712.
|
|
ZHU Bing, FAN Tianxin, ZHAO Jian, et al. Accelerate test method of automated driving system based on hazardous boundary search[J]. Journal of Jilin University: Engineering and Technology Edition, 2023, 53(3): 704-712.
|
| [7] |
FENG Shuo, YAN Xintao, SUN Haowei, et al. Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment[J]. Nature Communications, 2021, 12(1): DOI: 10.1038/s41467-021-21007-8.
|
| [8] |
FENG Shuo, SUN Haowei, YAN Xintao, et al. Dense reinforcement learning for safety validation of autonomous vehicles[J]. Nature, 2023, 615(7953): 620-627.
|
| [9] |
SUN Haowei, FENG Shuo, YAN Xintao, et al. Corner case generation and analysis for safety assessment of autonomous vehicles[J]. Transportation Research Record, 2021, 2675(11): 587-600.
|
| [10] |
李江坤, 邓伟文, 任秉韬, 等. 基于场景动力学和强化学习的自动驾驶边缘测试场景生成方法[J]. 汽车工程, 2022, 44 (7): 976-986.
|
|
LI Jiangkun, DENG Weiwen, REN Bingtao, et al. Automatic driving edge scene generation method based on scene dynamics and reinforcement learning[J]. Automotive Engineering, 2022, 44(7): 976-986.
|
| [11] |
ZHOU Ming, LUO Jun, VILLELLA J, et al. Smarts: an open-source scalable multi-agent reinforcement training school for autonomous driving[C]. Conference on Robot Learning, 2021: 264-285.
|
| [12] |
罗崎瑞, 张道文, 周华, 等. 面向智能汽车预期功能安全的驾驶场景评价[J]. 中国安全科学学报, 2022, 32(8):140-145.
doi: 10.16265/j.cnki.issn1003-3033.2022.08.1768
|
|
LUO Qirui, ZHANG Daowen, ZHOU Hua, et al. Evaluation on driving scenarios for safety of intended functionality of intelligent vehicles[J]. China Safety Science Journal, 2022, 32(8):140-145.
doi: 10.16265/j.cnki.issn1003-3033.2022.08.1768
|
| [13] |
胡祥旺, 倪颖, 孙剑. 车联网环境下匝道汇入区瓶颈换道优化[J]. 同济大学学报:自然科学版, 2023, 51(9):1424-1432.
|
|
HU Xiangwang, NI Ying, SUN Jian. Freeway merging area lane changing advisory optimization under connected vehicles environment[J]. Journal of Tongji University: Natural Science, 2023, 51(9): 1424-1432.
|
| [14] |
周文帅, 朱宇, 赵祥模, 等. 面向高速公路车辆切入场景的自动驾驶测试用例生成方法[J]. 汽车技术, 2021(1): 11-18.
|
|
ZHOU Wenshuai, ZHU Yu, ZHAO Xiangmo, et al. Vehicle cut-in test case generation methods for testing of autonomous driving on highway[J]. Automobile Technology, 2021(1): 11-18.
|
| [15] |
FUJIMOTO S, HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[C]. International Conference on Machine Learning (ICML), 2018: 1587-1596.
|
| [16] |
ZHOU Yang, CHEN Yunxing. Learning to drive in the NGSIM simulator using proximal policy optimization[J]. Journal of Advanced Transportation, 2023, 2023: DOI: 10.1155/2023/4127486.
|
| [17] |
CHEN Baiming, CHEN Xiang, WU Qiong, et al. Adversarial evaluation of autonomous vehicles in lane-change scenarios[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(8): 10 333-10 342.
|

 ), 陈运星2,3,**(
), 陈运星2,3,**( 京公网安备 11010502045206号
京公网安备 11010502045206号