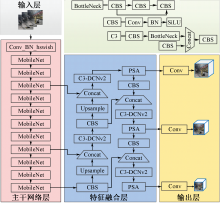
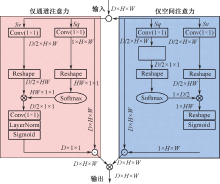
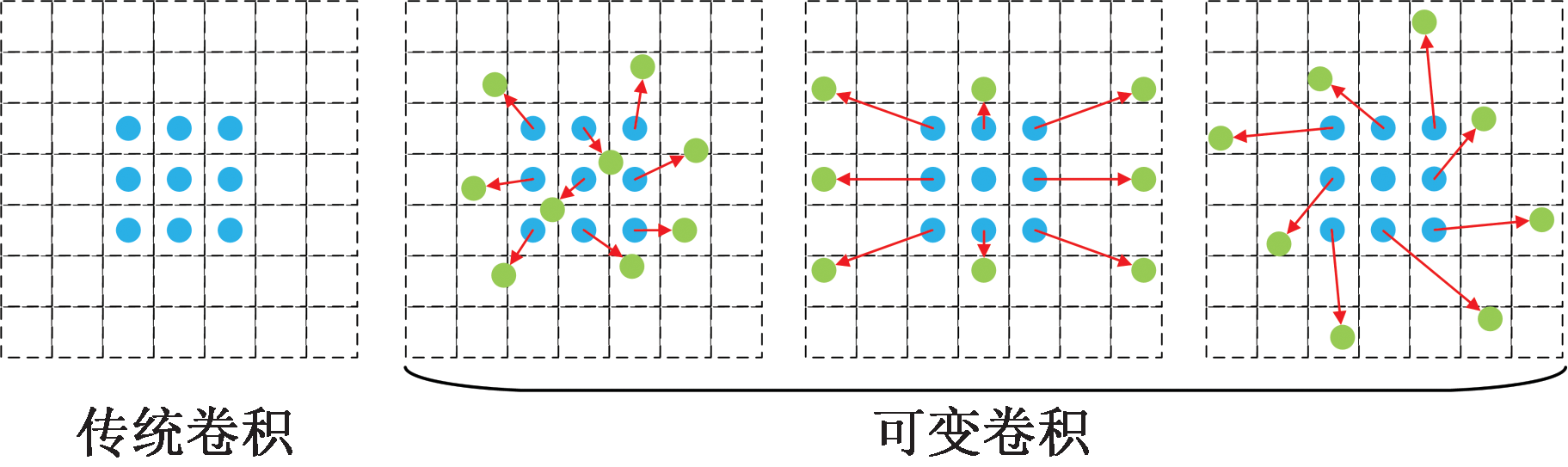
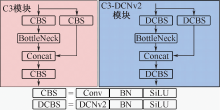
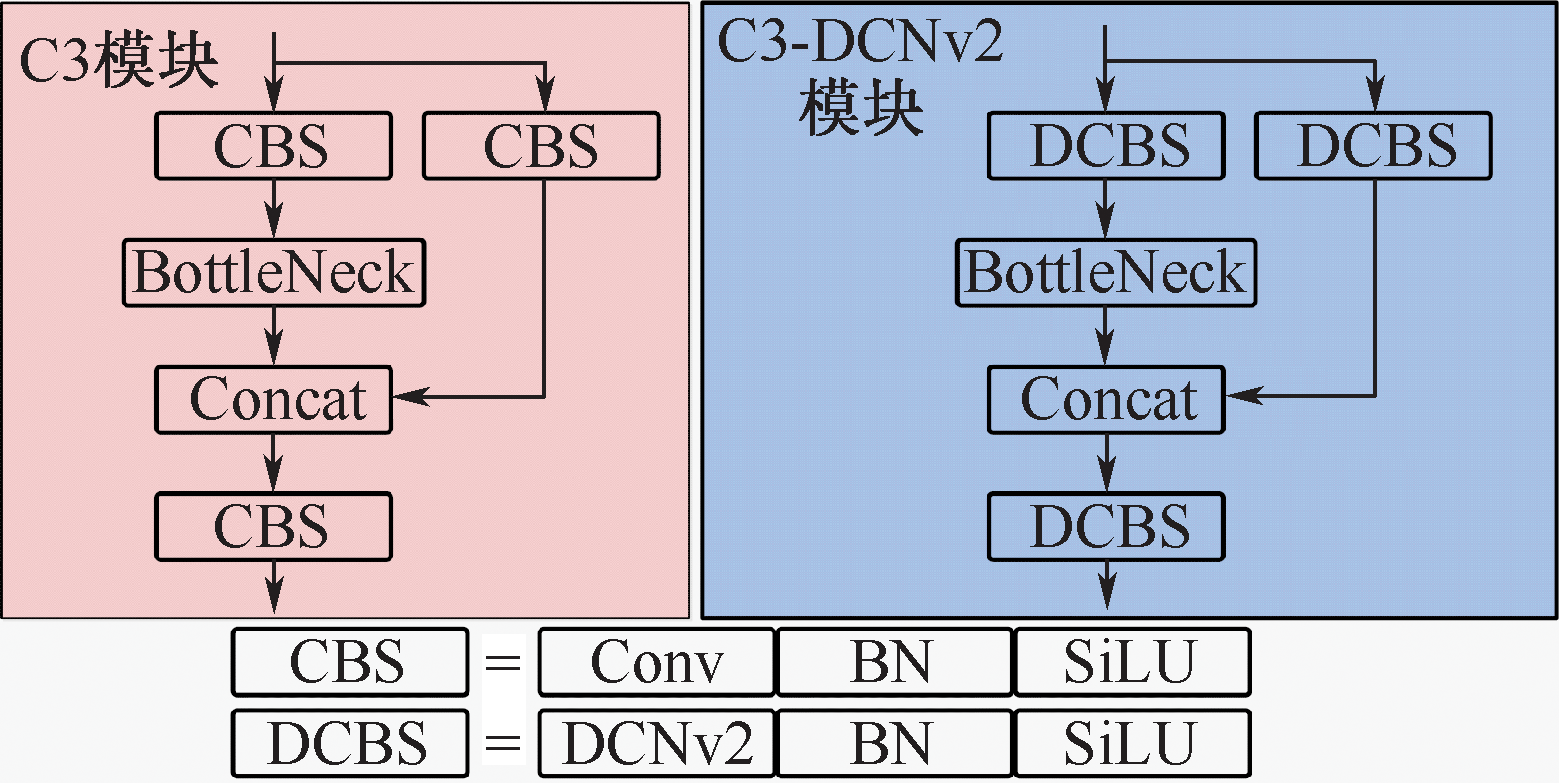
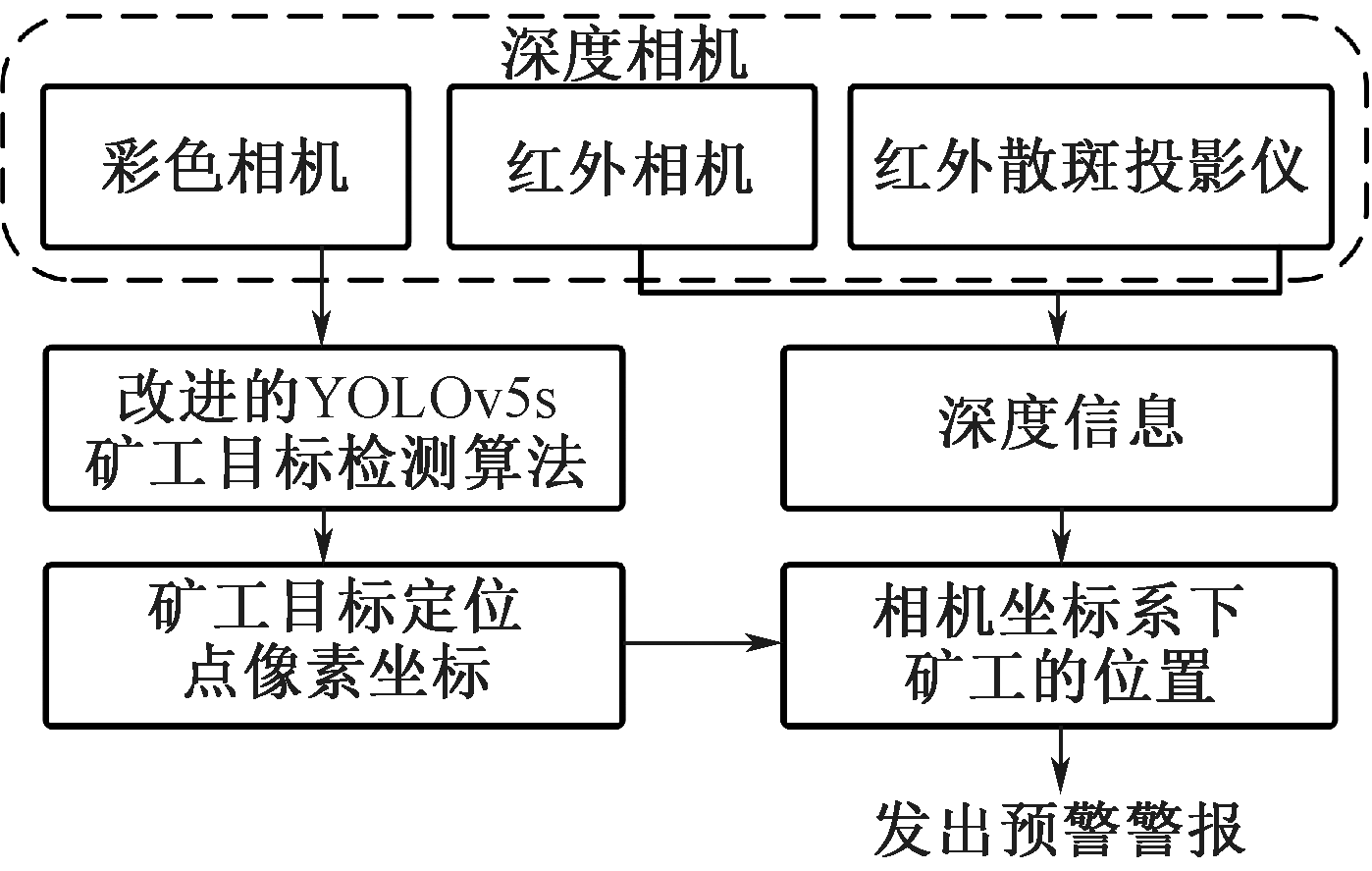
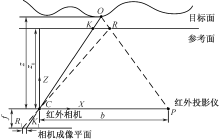
| [1] |
LI Ailing, ZHANG Jixiong, ZHOU Nan, et al. A model for evaluating the production system of an intelligent mine based on unascertained measurement theory[J]. Journal of Intelligent & Fuzzy Systems, 2020, 38(2): 1865-1875.
|
| [2] |
ZHANG Kexue, KANG Lei, CHEN Xuexi, et al. A review of intelligent unmanned mining current situation and development trend[J]. Energies, 2022, 15(2): DOI: 10.3390/en15020513.
|
| [3] |
付玉平, 陈兆波, 赵振保, 等. 煤矿安全事故的综合致因模型[J]. 安全与环境学报, 2024, 24(7): 2731-2740.
|
|
FU Yuping, CHEN Zhaobo, ZHAO Zhenbao, et al. Research on the comprehensive causative model of coal mine safety accidents[J]. Journal of Safety and Environment, 2024, 24(7): 2731-2740.
|
| [4] |
王国庆, 赵鑫, 杨春雨, 等. 煤矿地下空间定位技术研究进展[J]. 工程科学学报, 2024, 46(10): 1713-1727.
|
|
WANG Guoqing, ZHAO Xin, YANG Chunyu, et al. Recent advances in research on underground space positioning technology for coal mining[J]. Chinese Journal of Engineering, 2024, 46(10): 1713-1727.
|
| [5] |
孙哲星. 煤矿井下人员精确定位方法[J]. 煤炭科学技术, 2018, 46(3): 130-134.
|
|
SUN Zhexing. Personnel position method in underground coal mine[J]. Coal Science and Technology, 2018, 46(3): 130-134.
|
| [6] |
李梅, 姜展, 姜龙飞, 等. 三维可视化技术在智慧矿山领域的研究进展[J]. 煤炭科学技术, 2021, 49(2): 153-162.
|
|
LI Mei, JIANG Zhan, JIANG Longfei, et al. Research progress on 3D visualization technology for intelligent mine[J]. Coal Science and Technology, 2021, 49(2): 153-162.
|
| [7] |
左明成, 焦文华. 面向煤矿井下作业场景的安全帽佩戴识别算法[J]. 中国安全科学学报, 2024, 34(3): 237-246.
doi: 10.16265/j.cnki.issn1003-3033.2024.03.1985
|
|
ZUO Mingcheng, JIAO Wenhua. Helmet-wearing recognition algorithm for coal mine underground operation scenarios[J]. China Safety Science Journal, 2024, 34(3): 237-246.
doi: 10.16265/j.cnki.issn1003-3033.2024.03.1985
|
| [8] |
张磊, 李熙尉, 燕倩如, 等. 基于改进YOLOv5s的综采工作面人员检测算法[J]. 中国安全科学学报, 2023, 33(7): 82-89.
doi: 10.16265/j.cnki.issn1003-3033.2023.07.2226
|
|
ZHANG Lei, LI Xiwei, YAN Qianru, et al. Personnel detection algorithm in fully mechanized coal face based on improved YOLOv5s[J]. China Safety Science Journal, 2023, 33(7): 82-89.
doi: 10.16265/j.cnki.issn1003-3033.2023.07.2226
|
| [9] |
XIN Fangfang, HE Xinyu, YAO Chaoxiu, et al. A real-time detection for miner behavior via DYS-YOLOv8n model[J]. Journal of Real-Time Image Processing, 2024, 21(3): DOI: 10.1007/s11554-024-01466-0.
|
| [10] |
张春堂, 管利聪. 基于SSD-MobileNet的矿工安保穿戴设备检测系统[J]. 工矿自动化, 2019, 45(6): 96-100.
|
|
ZHANG Chuntang, GUAN Licong. Detection system of miners' wearable security equipments based on SSD-MobileNet[J]. Industry and Mine Automation, 2019, 45(6): 96-100.
|
| [11] |
郭永存, 童佳乐, 王爽. 井下无人驾驶电机车行驶场景中多目标检测研究[J]. 工矿自动化, 2022, 48(6): 56-63.
|
|
GUO Yongcun, TONG Jiale, WANG Shuang. Research on multi-object detection in driving scene of underground unmanned electric locomotive[J]. Journal of Mine Automation, 2022, 48(6): 56-63.
|
| [12] |
李伟山, 卫晨, 王琳. 改进的Faster RCNN煤矿井下行人检测算法[J]. 计算机工程与应用, 2019, 55(4): 200-207.
doi: 10.3778/j.issn.1002-8331.1711-0282
|
|
LI Weishan, WEI Chen, WANG Lin. Improved Faster RCNN approach for pedestrian detection in underground coal mine[J]. Computer Engineering and Applications, 2019, 55(4): 200-207.
doi: 10.3778/j.issn.1002-8331.1711-0282
|
| [13] |
王科平, 连凯海, 杨艺, 等. 基于改进YOLOv4的综采工作面目标检测[J]. 工矿自动化, 2023, 49(2): 70-76.
|
|
WANG Keping, LIAN Kaihai, YANG Yi, et al. Target detection of the fully mechanized working face based on improved YOLOv4[J]. Journal of Mine Automation, 2023, 49(2): 70-76.
|
| [14] |
郝明月, 闵冰冰, 张新建, 等. 基于改进YOLOv5s的矿工排队检测方法[J]. 工矿自动化, 2023, 49(11): 160-166.
|
|
HAO Mingyue, MIN Bingbing, ZHANG Xinjian, et al. A miner queue detection method based on improved YOLOv5s[J]. Journal of Mine Automation, 2023, 49(11): 160-166.
|
| [15] |
杨豚, 郭永存, 王爽, 等. 煤矿井下无人驾驶轨道电机车障碍物识别[J]. 浙江大学学报:工学版, 2024, 58(1): 29-39.
|
|
YANG Tun, GUO Yongcun, WANG Shuang, et al. Obstacle recognition of unmanned rail electric locomotive in underground coal mine[J]. Journal of Zhejiang University: Engineering Science, 2024, 58(1): 29-39.
|
| [16] |
郭曦, 谢炜, 朱红秀, 等. 井下目标跟踪与测距方法研究[J]. 煤炭工程, 2019, 51(3): 117-121.
doi: 10.11799/ce201903026
|
|
GUO Xi, XIE Wei, ZHU Hongxiu, et al. Target tracking and ranging method in underground mine[J]. Coal Engineering, 2019, 51(3): 117-121.
|
| [17] |
ZHOU Cheng, REN Dacong, ZHANG Xiangyan, et al. Human position detection based on depth camera image information in mechanical safety[J]. Advances in Mathematical Physics, 2022, 2022(1): DOI: 10.1155/2022/9170642.
|
| [18] |
韩江洪, 袁稼轩, 卫星, 等. 基于深度学习的井下巷道行人视觉定位算法[J]. 计算机应用, 2019, 39(3): 688-694.
doi: 10.11772/j.issn.1001-9081.2018071501
|
|
HAN Jianghong, YUAN Jiaxuan, WEI Xing, et al. Pedestrian visual positioning algorithm for underground roadway based on deep learning[J]. Journal of Computer Applications, 2019, 39(3): 688-694.
doi: 10.11772/j.issn.1001-9081.2018071501
|

 ), 王孝军1,2, 雷经发1,2,3,**(
), 王孝军1,2, 雷经发1,2,3,**( 京公网安备 11010502045206号
京公网安备 11010502045206号