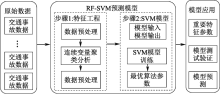
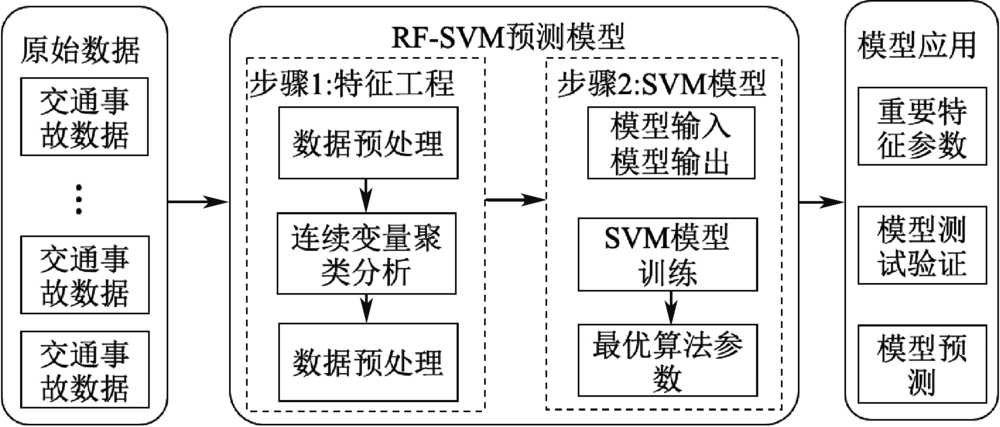
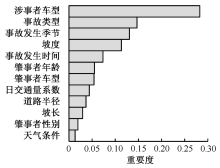
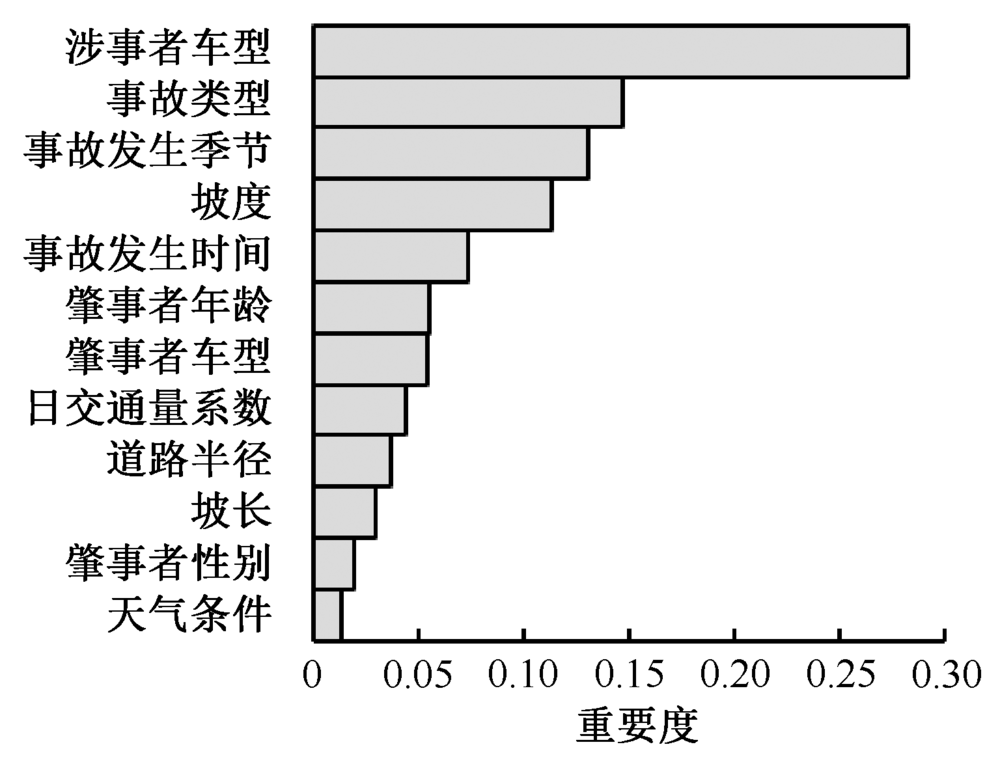
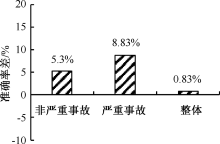
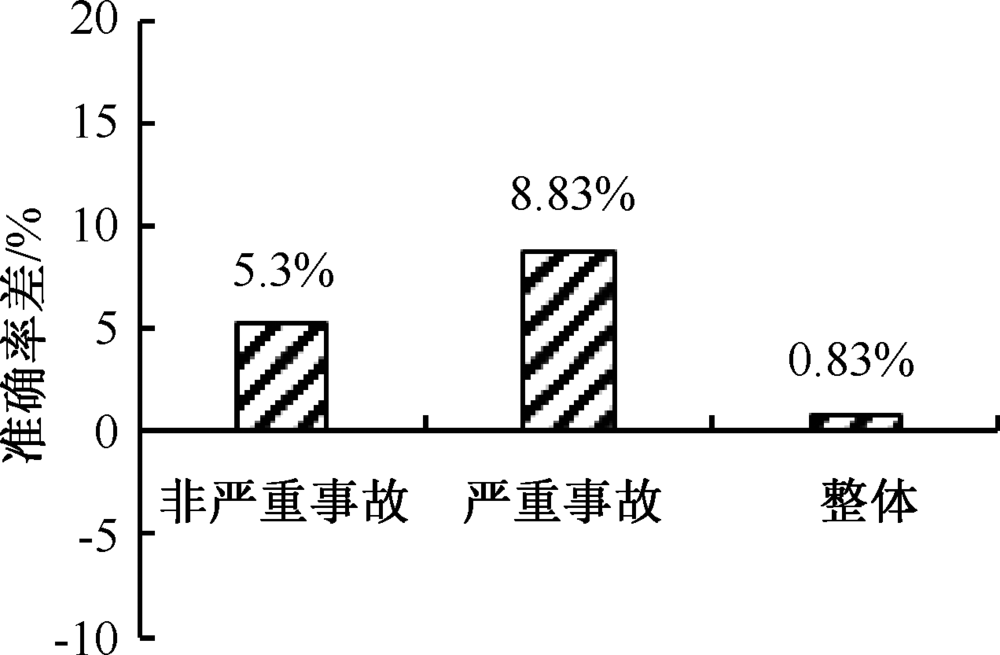
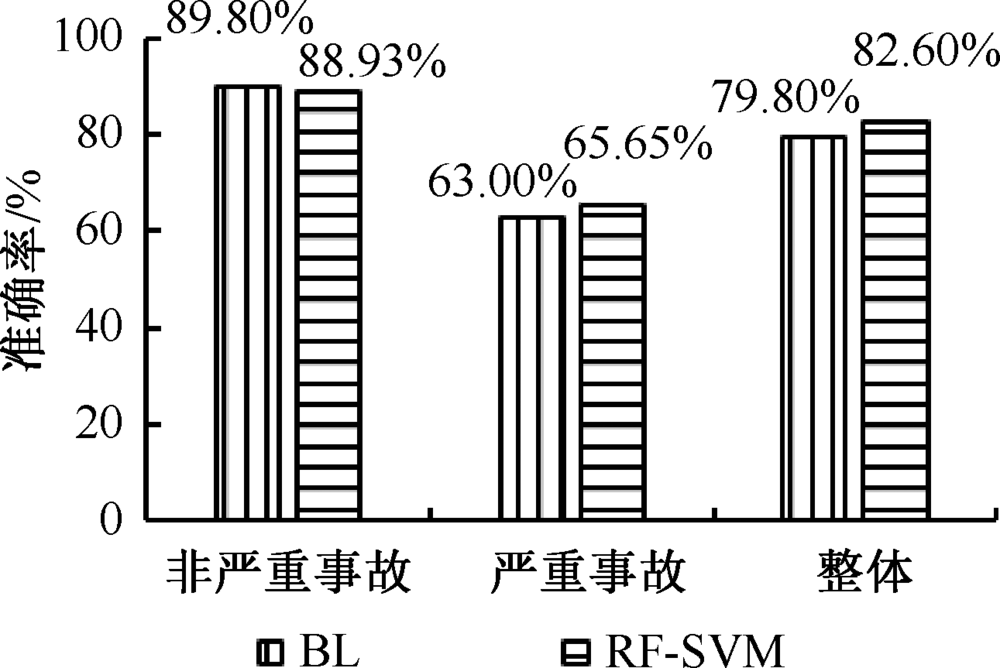
| [1] |
王建军, 曹旭东, 杨云峰. 基于CRSG模型的山区公路风险隔离研究[J]. 中国公路学报, 2018, 31(9):119-128.
|
|
WANG Jianjun, CAO Xudong, YANG Yunfeng. Risk isolation analysis of mountain highways areas based on CRSG model[J]. China Journal of Highway and Transport, 2018, 31(9):119-128.
|
| [2] |
MANNERING F L, BHAT C R. Analytic methods in accident research: methodological frontier and future directions[J]. Analytic Methods in Accident Research, 2014, 1: 1-22.
doi: 10.1016/j.amar.2013.09.001
|
| [3] |
MAMMERING F L, BHAT C, SHANKAR V, et al. Big data, traditional data and the tradeoffs between prediction and causality in highway-safety analysis[J]. Analytic Methods in Accident Research, 2020, 25: DOI: 10.1016/j.amar.2020.100113.
doi: 10.1016/j.amar.2020.100113
|
| [4] |
IRANITALAB A, KHATTAK A. Comparison of four statistical and machine learning methods for crash severity prediction[J]. Accident Analysis and Prevention, 2017, 108:27-36.
doi: 10.1016/j.aap.2017.08.008
|
| [5] |
戢晓峰, 李德林, 杨文臣, 等. 山区二级公路交通事故致因的时间演化机制[J]. 中国安全科学学报, 2019, 29(4):31-36.
doi: 10.16265/j.cnki.issn1003-3033.2019.04.006
|
|
JI Xiaofeng, LI Delin, YANG Wenchen, et al. Temporal evolution analysis on causes of traffic accidents occurring on secondary highways in mountain areas[J]. China Safety Science Journal, 2019, 29(4):31-36.
doi: 10.16265/j.cnki.issn1003-3033.2019.04.006
|
| [6] |
FOUNTAS G, ANASTASOPOULOS P C. A random thresholds random parameters hierarchical ordered probit analysis of highway accident injury-severities[J]. Analytic Methods in Accident Research, 2017, 15: 1-16.
doi: 10.1016/j.amar.2017.03.002
|
| [7] |
杨文臣, 谢碧珊, 房锐, 等. 山区双车道公路机动车碰撞事故严重度致因比较分析与预测[J]. 交通运输系统工程与信息, 2021, 21(1):190-195.
|
|
YANG Wenchen, XIE Bishan, FANG Rui, et al. Comparative analysis and prediction of motor vehicle crash severity on mountainous two-lane highways[J]. Journal of Transportation Systems Engineering and Information Technology, 2021, 21(1):190-195.
|
| [8] |
YU Rongjie, ABDEL-ATY M. Analyzing crash injury severity for a mountainous freeway incorporating real-time traffic and weather data[J]. Safety Science, 2014, 63(4):50-56.
doi: 10.1016/j.ssci.2013.10.012
|
| [9] |
马壮林, 张祎祎, 杨杨, 等. 公路隧道交通事故严重程度预测模型研究[J]. 中国安全科学学报, 2015, 25(5):75-79.
|
|
MA Zhuanglin, ZHANG Yiyi, YANG Yang, et al. Research on models for predicting severity of traffic accident in highway tunnel[J]. China Safety Science Journal, 2015, 25(5):75-79.
|
| [10] |
董傲然, 王长帅, 秦丹, 等. 机动车-行人事故中行人伤害严重程度分析[J]. 中国安全科学学报, 2020, 30(11): 141-147.
doi: 10.16265/j.cnki.issn 1003-3033.2020.11.021
|
|
DONG Aoran, WANG Changshuai, QIN Dan, et al. Analysis on injury severity of pedestrian in motor vehicle-pedestrian accidents[J]. China Safety Science Journal, 2020, 30(11): 141-147.
doi: 10.16265/j.cnki.issn 1003-3033.2020.11.021
|
| [11] |
ZHU Li, YU Fei Richard, WANG Yige, et al. Big data analytics in intelligent transportation systems: a survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 20(1): 383-398.
doi: 10.1109/TITS.2018.2815678
|
| [12] |
YU Rongjie, ABEDEL-ATY M. Utilizing support vector machine in real-time crash risk evaluation[J]. Accident Analysis and Prevention, 2013, 51:252-259.
doi: 10.1016/j.aap.2012.11.027
|
| [13] |
游锦明, 王俊骅, 唐棠, 等. 基于支持向量机的高速公路实时事故风险研判[J]. 同济大学学报:自然科学版, 2017, 45(3):355-361.
|
|
YOU Jinming, WANG Junye, TANG Tang, et al. Support vector machines approach for predicting real-time rear-end crash risk on freeways[J]. Journal of Tongji University: Natural Science, 2017, 45(3):355-361.
|
| [14] |
SUN Ming, SUN Xiaoduan, SHAN Donghui. Pedestrian crash analysis with latent class clustering method[J]. Accident Analysis and Prevention, 2019, 124:50-57.
doi: 10.1016/j.aap.2018.12.016
|
| [15] |
SILVA P B, ANDRADE M, FERREIR A S. Machine learning applied to road safety modeling: a systematic literature review[J]. Journal of Traffic and Transportation Engineering: English edition, 2020, 7(6):775-790.
|
| [16] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 121-204.
|
|
ZHOU Zhihua. Machine learning[M]. Beijing: Tsinghua University Press, 2016:121-204.
|